

As the era of Artificial Intelligence (AI) dawns, data has become the core resource for innovation and competitiveness in enterprises. From healthcare to fintech, from smart cities to manufacturing, data-driven applications are rapidly transforming industries across the board.


Four key features offer unique advantages and applications, helping enterprises process data more efficiently and improve decision-making effectiveness and accuracy.
As a powerful data processing engine, Spark is a key component of Hare. In the new version of Hare, Spark’s role will be further enhanced, offering not only batch data processing but also improved real-time data processing capabilities. With its in-memory computing technology and rich ecosystem (including Spark SQL, Spark Streaming, and MLlib), Spark will assist businesses in tackling more complex data processing challenges, particularly in AI model training and prediction applications.
In the new version of Hare, the introduction of Object Storage will significantly boost the flexibility and scalability of data storage. Unlike traditional HDFS, Object Storage efficiently handles unstructured data and supports on-demand storage expansion, leading to substantial reductions in storage and management costs. This is especially crucial for AI applications that require processing large volumes of images, videos, and other unstructured data.
Iceberg is a new open table format for data lakes that enhances both management and query efficiency. In the new version of Hare, the integration of Iceberg will offer improved data management and query performance, supporting features such as time-travel queries and efficient partition management. This makes the data lake more flexible and user-friendly, particularly suited for AI applications that require frequent data updates and queries.
As a next-generation distributed query engine, Trino will significantly enhance Hare’s data querying capabilities. It supports high-performance SQL queries across multiple data sources, including Object Storage, relational databases, and HDFS. This enables enterprises to more flexibly and efficiently extract valuable insights from vast amounts of data, improving decision-making efficiency and accuracy.
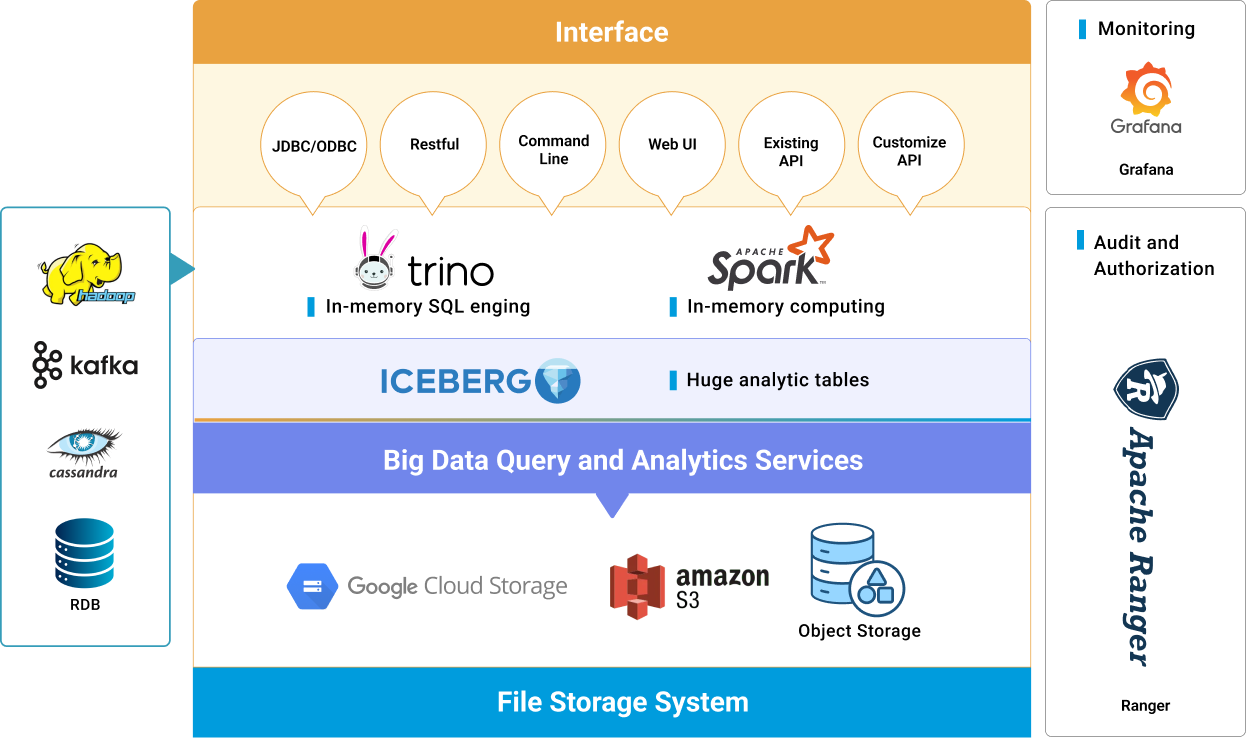
The Hare Data Platform enables enterprises to handle data more efficiently and improve decision-making accuracy, allowing businesses to swiftly adapt to the AI era.

